Исключения
В нашем разговоре о потоке исполнения команд различными подсистемами пришло время поговорить про исключения или, скорее, исключительные ситуации. И прежде чем продолжить стоит совсем немного остановиться именно на самом определении. Что такое исключительная ситуация? Это такая ситуация, которая делает исполнение дальнейшего или текущего кода абсолютно не корректным. Не таким как задумывалось, проектировалось. Переводит состояние приложения в целом или же его отделой части (например, объекта) в состояние нарушенной целостности. Т.е. что-то экстраординарное, исключительное.
Почему это так важно - определить терминологию? Работа с терминологией очень важна, т.к. она держит нас в рамках. Вот, например: будет ли являться исключительной ситуация когда пользователь ввел в поле ввода чисел букву 'a'? Наверное, нет: мы можем легко проигнорировать ввод. Но если мы поделим любое целое число на ноль это будет исключительной ситуацией: на ноль делить нельзя. Дальнейшее выполнение программы бессмысленно, т.к. расчеты гарантированно не корректны. Исключительные ситуации, возникающие в приложении должны прерывать исполнение текущего, уже более не корректного, кода и искать способы исправить ситуацию. Здесь я попрошу вас обратить внимание на слово "прерывать". Оно очень интересно в первую очередь тем что помимо механизма исключений существует еще один механизм: механизм прерываний. И разница между этими двумя механизмами состоит в том что прерывания останавливают приложение на время, выполняют некоторый код и продолжают выполнение кода программы тогда как исключения работают известным всеми способом: полностью обрубают выполнение кода текущего метода, уводя поток исполнения инструкций процессором в выше-стоящие методы, способные возникшую ошибку обработать.
О чем пойдет речь в этом разделе:
- Состав и развертка блока обработки исключительных ситуаций
- События о исключительных ситуациях:
AppDomain.FirstChanceExceptionиAppDomain.UnhandledException - Виды исключений: что тянется из CLR, а что - из более низкого слоя (Windows SEH)
- Исключения с особым поведением: ThreadAbortException, OutOfMemoryException и прочие
- Каким образом идет сборка стека вызовов и производительность выброса исключений
- Асинхронные исключения
- Structured Exception Handling
- Vectored Exception Handling
- Прерывания
Состав и развертка блока обработки исключительных ситуаций
Общая картина
Если взглянуть на блок обработки исключительных ситуаций, то мы увидим всем привычную картину:
try {
// 1
} catch (ArgumentsOutOfRangeException exception)
{
// 2
} catch (IOException exception)
{
// 3
} catch
{
// 4
} finally {
// 5
}
Т.е. существует некий участок кода от которого ожидается некоторое нарушение поведения. Причем не просто некоторое, а вполне конкретные ситуации. Однако, если заглянуть в результирующий код, то мы увидим что по факту эта самая конструкция, которая в C# выглядит как единое целое, в CLI на самом деле разделена на отдельные блоки. Т.е. не существует возможности построить вот такую единую цепочку обработки ошибок, однако есть возможность построить для одного и того же участка отдельные блоки try-catch и try-finally. И если переводить MSIL обратно в C#, то получим мы следующий код:
try {
try {
try {
try {
// 1
} catch (ArgumentsOutOfRangeException exception)
{
// 2
}
} catch (IOException exception)
{
// 3
}
} catch
{
// 4
}
} finally {
// 5
}
// 6
Отлично. Однако если мы хотим увидеть картину с точки зрения "как оно все устроено", то полученный код выглядит все же несколько искусственно. Ведь эти блоки - конструкции языка и не более того. Как они разворачиваются в конечном коде? На данном этапе я ограничусь псевдокодом, однако без лишних подробностей он прекрасно покажет во что примерно разворачивается конструкция:
GlobalHandlers.Push(BlockType.Finally, FinallyLabel);
GlobalHandlers.Push(BlockType.Catch, typeof(Exception), ExceptionCatchLabel);
GlobalHandlers.Push(BlockType.Catch, typeof(IOException), IOExceptionCatchLabel);
GlobalHandlers.Push(BlockType.Catch, typeof(ArgumentsOutOfRangeException), ArgumentsOutOfRangeExceptionCatchLabel);
// 1
GlobalHandlers.Pop(4);
FinallyLabel:
// 5
goto AfterTryBlockLabel;
ExceptionCatchLabel:
GlobalHandlers.Pop(4);
// 4
goto FinallyLabel;
IOExceptionCatchLabel:
GlobalHandlers.Pop(4);
// 3
goto FinallyLabel;
ArgumentsOutOfRangeExceptionCatchLabel:
GlobalHandlers.Pop(4);
// 2
goto FinallyLabel;
AfterTryBlockLabel:
// 6
return;
Также о чем хотелось бы упомянуть во вводной части - это фильтры исключительных ситуаций. Для платформы .NET это новшеством не является, однако является таковым для разработчиков на языке программирования C#: фильтрация исключительных ситуаций появилась у нас только в шестой версии языка. Особенностью исполнения кода по уверениям многих источников является то, что код фильтрации происходит до того как произойдет развертка стека. Это можно наблюдать в ситуациях, когда между местом выброса исключения и местом проверки на фильтрацию нет никаких других вызовов кроме обычных:
static void Main()
{
try
{
Foo();
}
catch (Exception ex) when (Check(ex))
{
;
}
}
static void Foo()
{
Boo();
}
static void Boo()
{
throw new Exception("1");
}
static bool Check(Exception ex)
{
return ex.Message == "1";
}
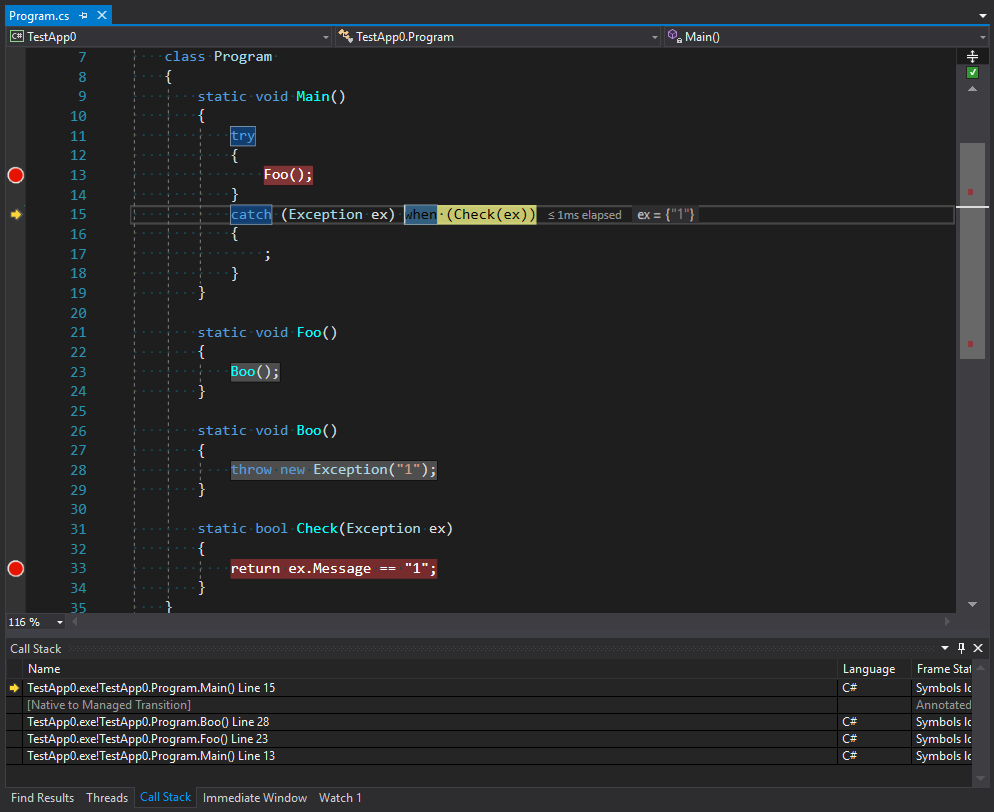
Как видно на изображении трассировка стека содержит не только первый вызов Main как место отлова исключительной ситуации, но и весь стек до точки выброса исключения плюс повторный вход в Main через некоторый неуправляемый код. Можно предположить что этот код и есть код выброса исключений, который просто находится в стадии фильтрации и выбора конечного обработчика. Однако стоит отметить что не все вызовы позволяют работать без раскрутки стека. Если посмотреть на результаты работы следующего кода (я добавил проброс вызова через границу между доменами приложения):
class Program
{
static void Main()
{
try
{
ProxyRunner.Go();
}
catch (Exception ex) when (Check(ex))
{
;
}
}
static bool Check(Exception ex)
{
var domain = AppDomain.CurrentDomain.FriendlyName; // -> TestApp.exe
return ex.Message == "1";
}
public class ProxyRunner : MarshalByRefObject
{
private void MethodInsideAppDomain()
{
throw new Exception("1");
}
public static void Go()
{
var dom = AppDomain.CreateDomain("PseudoIsolated", null, new AppDomainSetup
{
ApplicationBase = AppDomain.CurrentDomain.BaseDirectory
});
var proxy = (ProxyRunner) dom.CreateInstanceAndUnwrap(typeof(ProxyRunner).Assembly.FullName, typeof(ProxyRunner).FullName);
proxy.MethodInsideAppDomain();
}
}
}
То станет ясно что размотка стека в данном случае происходит еще до того как мы попадаем в фильтр. Взглянем на скриншоты. Первый взят до того как генерируется исключение:
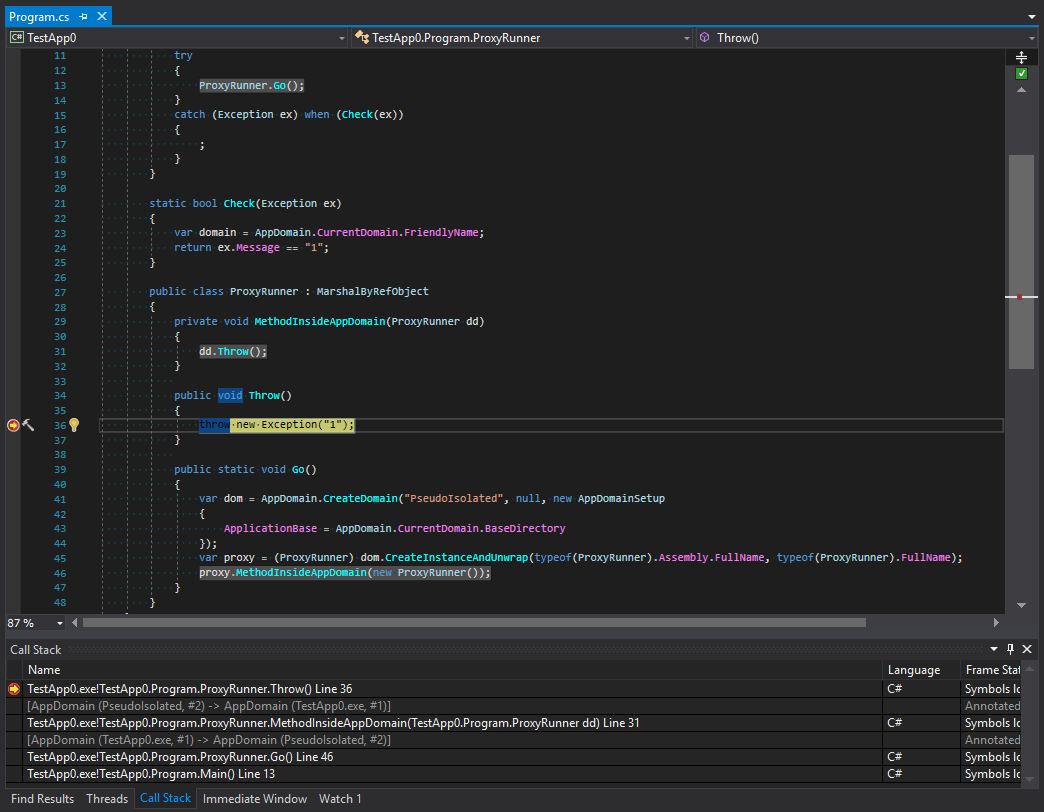
А второй - после:
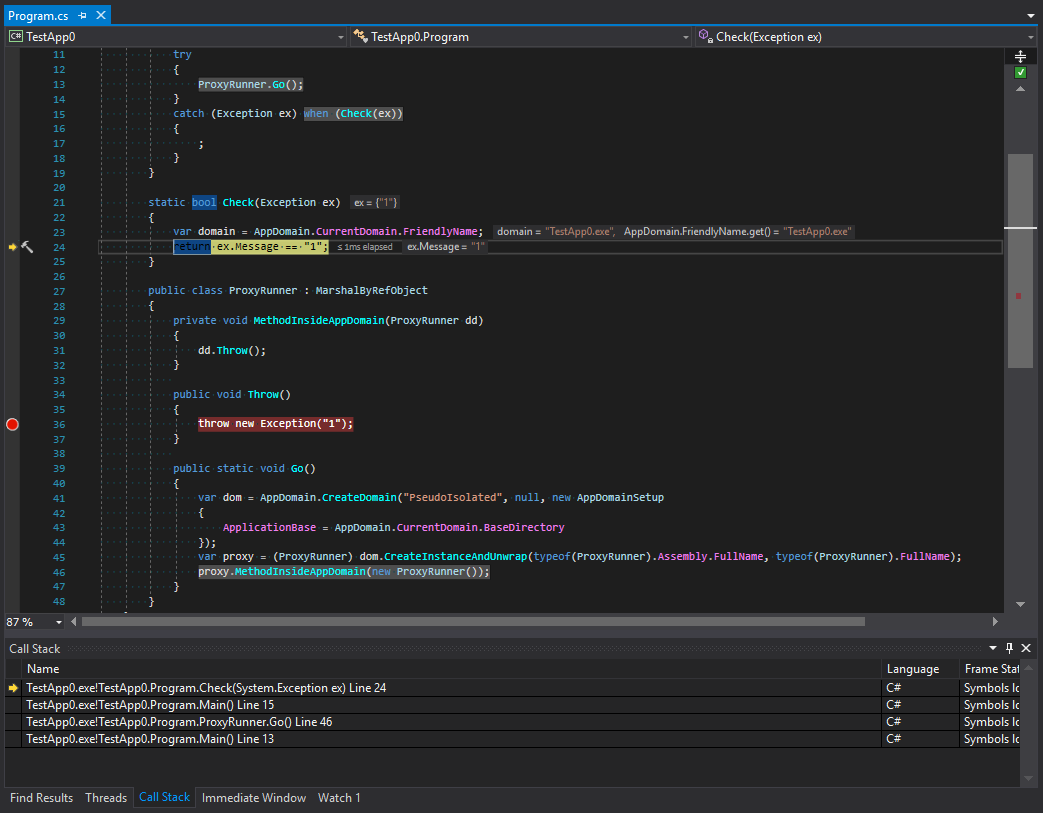
Изучим трассировку вызовов до и после попадания в фильтр исключений. Что же здесь происходит? Здесь мы видим что разработчики платформы сделали некоторую с первого взгляда защиту дочернего домена. Трассировка обрезана по крайний метод в цепочке вызовов, после которого идет переход в другой домен. На самом деле как по мне так это выглядит несколько странно. Чтобы понять, почему так происходит, вспомним основное правило для типов, организующих взаимодействие между доменами. Типы должны наследовать MarshalByRefObject плюс - быть сериализуемыми. Однако как бы ни был строг C#, типы исключений могут быть какими угодно. Это могут быть вовсе не Exception-based типы. А что это значит? Это значит что могут быть ситуации, когда исключительная ситуация внутри дочернего домена может привести у уводу в родительский домен объекта, который передан по ссылке, и у которого есть какие-либо опасные методы с точки зрения безопасности. Чтобы такого избежать, исключение сериализуется, проходит через границу доменов приложений и возникает вновь - с новым стеком. Давайте проверим эту стройную теорию:
[StructLayout(LayoutKind.Explicit)]
class Cast
{
[FieldOffset(0)]
public Exception Exception;
[FieldOffset(0)]
public object obj;
}
static void Main()
{
try
{
ProxyRunner.Go();
Console.ReadKey();
}
catch (RuntimeWrappedException ex) when (ex.WrappedException is Program)
{
;
}
}
static bool Check(Exception ex)
{
var domain = AppDomain.CurrentDomain.FriendlyName; // -> TestApp.exe
return ex.Message == "1";
}
public class ProxyRunner : MarshalByRefObject
{
private void MethodInsideAppDomain()
{
var x = new Cast {obj = new Program()};
throw x.Exception;
}
public static void Go()
{
var dom = AppDomain.CreateDomain("PseudoIsolated", null, new AppDomainSetup
{
ApplicationBase = AppDomain.CurrentDomain.BaseDirectory
});
var proxy = (ProxyRunner)dom.CreateInstanceAndUnwrap(typeof(ProxyRunner).Assembly.FullName, typeof(ProxyRunner).FullName);
proxy.MethodInsideAppDomain();
}
}
В данном примере для того чтобы выбросить исключение любого типа из C# кода (я не хочу никого мучать вставками на MSIL) был проделан трюк с приведением типа к не сопоставимому: чтобы мы бросили исключение любого типа, а транслятор C# думал бы что мы используем тип Exception. Мы создаем экземпляр типа Program - гарантированно не сериализуемого и бросаем исключение с ним в виде полезной нагрузки. Хорошие новости заключаются в том что вы получите обертку над не-Exception исключениями RuntimeWrappedException, который внутри себя сохранит экземпляр нашего объекта типа Program и в C# перехватить такое исключение мы сможем. Однако есть и плохая новость, которая подтверждает наше предположение: вызов proxy.MethodInsideAppDomain(); приведет к исключению SerializationException:

Т.е. проброс между доменами такого исключения не возможен, т.к. его нет возможности сериализовать. А это в свою очередь значит что оборачивание вызовов методов, находящихся в других доменах фильтрами исключений все равно приведет к развертке стека несмотря на то что при FullTrust настройках дочернего домена сериализация казалось бы не нужна.
Стоит дополнительно обратить внимание на причину, по которой сериализация между доменами так необходима. В нашем синтетическом примере мы создаем дочерний домен, который не имеет никаких настроек. А это значит что он работает в FullTrust. Т.е. CLR полностью доверяет его содержимому как себе и никаких дополнительных проверок делать не будет. Но как только вы выставите хоть одну настройку безопасности, полная доверенность пропадет и CLR начнет контролировать все что происходит внутри этого дочернего домена. Так вот когда домен полностью доверенный, сериализация по-идее не нужна. Нам нет необходимости как-то защищаться, согласитесь. Но сериализация создана не только для защиты. Каждый домен грузит библиотеки в себя по второму разу, создавая их копии. Тем самым создавая копии всех типов и всех таблиц виртуальных методов. Передавая объект по ссылке из домена в домен вы получите, конечно, тот же объект. Но у него будут чужие таблицы виртуальных методов и как результат - этот объект не сможет быть приведен к другому типу. Другими словами, если вы создали экземпляр типа
Boo, то получив его в другом домене приведение типа(Boo)booне сработает. А сериализация и десериализация решает проблему
Передавая серализуемый объект между доменами вы получите в другом домене полную копию объекта из первого сохранив некоторую разграниченность по памяти. Разграниченность тоже мнимая. Она - только для тех типов, которые не находятся в Shared AppDomain. Т.е., например, если в качестве исключения бросить что-нибудь несериализуемое, но из Shared AppDomain, то ошибки сериализации не будет (можно попробовать вместо Program бросить Action). Однако раскрутка стека при этом все равно произойдет: оба случая должны работать стандартно. Чтобы никого не путать.
События об исключительных ситуациях
В общем случае мы не всегда знаем о тех исключениях, которые произойдут в наших программах потому что практчески всегда мы используем что-то, что написано другими людьми и что находится в других подсистемах и библиотеках. Мало того что возможны самые разные ситуации в вашем собственном коде, так еще и существует множество проблем, связанных с исполнением кода в изоблированных доменах. И как раз в этом случае было бы крайне полезно уметь получать данные о работе изолированного кода. Ведь вполне реальной может быть ситуация, когда сторонний код перехватывает все без исключения ошибки, заглушив их fault блоком:
try {
// ...
} catch {
// do nothing, just to make code call more safe
}
В такой ситуации может оказаться что выполнение кода уже не так безопасно как выглядит, но сообщений о том что произошли какие-то проблемы мы не имеем. Второй вариант - когда приложение глушит некоторое, пусть даже легальное, исключение. А результат - следующее исключение в случайном месте - падение приложения в некотором будущем от случайной казалось бы ошибки. Тут хотелось бы иметь представление, какая была предыстория этой ошибки. Каков ход событий привел к такой ситуации. Один из способов сделать это возможным - использовать дополнительные события, которые относятся к исключительным ситуациям: AppDomain.FirstChanceException и AppDomain.UnhandledException.
Фактически, когда вы "бросаете исключение", то вызывается обычный метод некоторой внутренней подсистемы Throw, который внутри себя проделывает следующие операции:
- Вызывает
AppDomain.FirstChanceException - Ищет в цепочке обработчиков подходящий по фильтрам
- Вызывает обработчик предварительно откатив стек на нужный кадр
- Если обработчик найден не был, вызывается
AppDomain.UnhandledException, обрушивая поток, в котором произошло исключение.
Сразу следует оговориться, ответив на мучающий многие умы вопрос: есть ли возможность как-то обработать исключение, не обрушивая тем самым поток, в котором это исключение было выброшено? Ответ лаконичен и прост: нет. Если исключение не перехватывается на всем диапазоне вызванных методов, оно не может быть обработано в принципе. Иначе возникает странная ситуация: если мы при помощи AppDomain.FirstChanceException обрабатываем (некий синтетический catch) исключение, то на какой кадр должен откатитья стек потока? Как это задать в рамках правил .NET CLR? Никак. Это просто не возможно. Единственное что мы можем сделать - запротоколировать полученную информацию для будущих исследований.
Второе, о чем следует рассказать "на берегу" - это почему эти события введены не у Thread, а у AppDomain. Ведь если следовать логике, исключения возникают где? В потоке исполнения команд. Т.е. фактически у Thread. Так почему же проблемы возникают у домена? Ответ очень прост: для каких ситуаций создавались AppDomain.FirstChanceException и AppDomain.UnhandledException? Помимо всего прочего - для создания песочниц для плагинов. Т.е. для ситуаций, когда есть некий AppDomain, который настроен на PartialTrust. Внутри этого AppDomain может происходить что угодно, создаются потоки, используются уже существующие из ThreadPool. Тогда получается что мы, будучи находясь снаружи от этого процесса (не мы писали тот код) не можем никак подписаться на события внутренних потоков. Просто потому что мы понятия не имеем что там за потоки были созданы. Зато мы гарантированно имеем AppDomain, который организует песочницу и ссылка на который у нас есть.
Итак, по факту нам предоставляется два краевых события: что-то произошло, чего не предполагалось (FirstChanceExecption) и "все плохо", никто не обработал исключительную ситуацию: она оказалась не предусмотренной. А потому поток исполнения команд не имеет смысла и он (Thread) будет отгружен.
Что можно получить, имея данные события и почему плохо что разработчики обходят эти события стороной?
AppDomain.FirstChanceException
Это событие по своей сути носит чисто информационный характер и не может быть "обработано". Его задача - уведомить вас что в рамках данного домена произошло исключение и оно после обработки события начнет обрабатываться кодом приложения. Его исполнение несет за собой пару особенностей, о которых необходимо помнить во время проектирования обработчика.
Но давайте для начала посмотрим на простой синтетический пример его обработки:
void Main()
{
var counter = 0;
AppDomain.CurrentDomain.FirstChanceException += (_, args) => {
Console.WriteLine(args.Exception.Message);
if(++counter == 1) {
throw new ArgumentOutOfRangeException();
}
};
throw new Exception("Hello!");
}
Чем примечателен данный код? Где бы некий код ни сгенерировал бы исключение первое что произойдет - это его логгирование в консоль. Т.е. даже если вы забудете или не сможете предусмотреть обработку некоторого типа исключения оно все равно появится в журнале событий, которое вы организуете. Второе - несколько странное условие выброса внутреннего исключения. Все дело в том что внутри обработчика FirstChanceException вы не можете просто взять и бросить еще одно исключение. Скорее даже так: внутри обработчика FirstChanceException вы не имеете возможности бросить хоть какое-либо исключение. Если вы так сделаете, возможны два варианта событий. При первом, если бы не было условия if(++counter == 1), мы бы получили бесконечный выброс FirstChanceException для все новых и новых ArgumentOutOfRangeException. А что это значит? Это значит что на определенном этапе мы бы получили StackOverflowException: throw new Exception("Hello!") вызывает CLR метод Throw, который вызывает FirstChanceException, который вызывает Throw уже для ArgumentOutOfRangeException и далее - по рекурсии. Второй вариант - мы защитились по глубине рекурсии при помощи условия по counter. Т.е. в данном случае мы бросаем исключение только один раз. Результат более чем неожиданный: мы получим исключительную ситуацию, которая фактически отрабатывает внутри инструкции Throw. А что подходит более всего для данного типа ошибки? Согласно ECMA-335 если инструкция была введена в исключительное положение, должно быть выброшено ExecutionEngineException! А эту исключительную ситуацию мы обработать никак не в состоянии. Она приводит к полному вылету из приложения. Какие же варианты безопасной обработки у нас есть?
Первое, что приходит в голову - это выставить try-catch блок на весь код обработчика FirstChanceException:
void Main()
{
var fceStarted = false;
var sync = new object();
EventHandler<FirstChanceExceptionEventArgs> handler;
handler = new EventHandler<FirstChanceExceptionEventArgs>((_, args) =>
{
lock (sync)
{
if (fceStarted)
{
// Этот код по сути - заглушка, призванная уведомить что исключение по своей сути - родилось не в основном коде приложения,
// а в try блоке ниже.
Console.WriteLine($"FirstChanceException inside FirstChanceException ({args.Exception.GetType().FullName})");
return;
}
fceStarted = true;
try
{
// не безопасное логгирование куда угодно. Например, в БД
Console.WriteLine(args.Exception.Message);
throw new ArgumentOutOfRangeException();
}
catch (Exception exception)
{
// это логгирование должно быть максимально безопасным
Console.WriteLine("Success");
}
finally
{
fceStarted = false;
}
}
});
AppDomain.CurrentDomain.FirstChanceException += handler;
try
{
throw new Exception("Hello!");
} finally {
AppDomain.CurrentDomain.FirstChanceException -= handler;
}
}
OUTPUT:
Hello!
Specified argument was out of the range of valid values.
FirstChanceException inside FirstChanceException (System.ArgumentOutOfRangeException)
Success
!Exception: Hello!
Т.е. с одной стороны у нас есть код обработки события FirstChanceException, а с другой - дополнительный код обработки исключений в самом FirstChanceException. Однако методики логгирования обоих ситуаций должны отличаться. Если логгирование обработки события может идти как угодно, то обработка ошибки логики обработки FirstChanceException должно идти без исключительных ситуаций в принципе. Второе, что вы наверняка заметили - это синхронизация между потоками. Тут может возникнуть вопрос: зачем она тут если любое исключение рождено в каком-либо потоке а значит FirstChanceException по-идее должен быть потокобезопасным. Однако, все не так жизнерадостно. FirstChanceException у нас возникает у AppDomain. А это значит, что он возникает для любого потока, стартованного в определенном домене. Т.е. если у нас есть домен, внутри которого стартовано несколько потоков, то FirstChanceException могут идти в параллель. А это значит что нам необходимо как-то защитить себя синхронизацией: например при помощи lock.
Второй способ - попробовать увести обработку в соседний поток, принадлежащий другому домену приложений. Однако тут стоит оговориться что при такой реализации мы должны построить выделенный домен именно под эту задачу чтобы не получилось так что этот домен могут положить другие потоки, которые являются рабочими:
static void Main()
{
using (ApplicationLogger.Go(AppDomain.CurrentDomain))
{
throw new Exception("Hello!");
}
}
public class ApplicationLogger : MarshalByRefObject
{
ConcurrentQueue<Exception> queue = new ConcurrentQueue<Exception>();
CancellationTokenSource cancellation;
ManualResetEvent @event;
public void LogFCE(Exception message)
{
queue.Enqueue(message);
}
private void StartThread()
{
cancellation = new CancellationTokenSource();
@event = new ManualResetEvent(false);
var thread = new Thread(() =>
{
while (!cancellation.IsCancellationRequested)
{
if (queue.TryDequeue(out var exception))
{
Console.WriteLine(exception.Message);
}
Thread.Yield();
}
@event.Set();
});
thread.Start();
}
private void StopAndWait()
{
cancellation.Cancel();
@event.WaitOne();
}
public static IDisposable Go(AppDomain observable)
{
var dom = AppDomain.CreateDomain("ApplicationLogger", null, new AppDomainSetup
{
ApplicationBase = AppDomain.CurrentDomain.BaseDirectory,
});
var proxy = (ApplicationLogger)dom.CreateInstanceAndUnwrap(typeof(ApplicationLogger).Assembly.FullName, typeof(ApplicationLogger).FullName);
proxy.StartThread();
var subscription = new EventHandler<FirstChanceExceptionEventArgs>((_, args) =>
{
proxy.LogFCE(args.Exception);
});
observable.FirstChanceException += subscription;
return new Subscription(() => {
observable.FirstChanceException -= subscription;
proxy.StopAndWait();
});
}
private class Subscription : IDisposable
{
Action act;
public Subscription (Action act) {
this.act = act;
}
public void Dispose()
{
act();
}
}
}
В данном случае обработка FirstChanceException происходит максимально безопасно: в соседнем потоке, принадлежащим соседнему домену. Ошибки обработки сообщения при этом не могут обрушить рабочие потоки приложения. Плюс отдельно можно послушать UnhandledException домена логгирования сообщений: фатальные ошибки при логгировании не обрушат все приложение.
AppDomain.UnhandledException
Второе сообщение, которое мы можем перехватить и которое касается обработки исключительных ситуаций - это AppDomain.UnhandledException. Это сообщение - очень плохая новость для нас поскольку обозначает что не нашлось никого кто смог бы найти способ обработки возникшей ошибки в некотором потоке. Также, если произошла такая ситуация, все что мы можем сделать - это "разгрести" последствия такой ошибки. Т.е. каким-либо образом зачистить ресурсы, принадлежащие только этому потоку если таковые создавались. Однако, еще более лучшая ситуация - обрабатывать исключения, находясь в "корне" потоков не заваливая поток. Т.е. по сути ставить try-catch. Давайте попробуем рассмотреть целесообразность такого поведения.
Пусть мы имеем библиотеку, которой необходимо создавать потоки и осуществлять какую-то логику в этих потоках. Мы, как пользователи этой библиотеки интересуемся только гарантией вызовов API а также получением сообщений об ошибках. Если библиотека будет рушить потоки не нотифицируя об этом, нам это мало чем может помочь. Мало того обрушение потока приведет к сообщению AppDomain.UnhandledException, в котором нет информации о том, какой конкретно поток лег на бок. Если же речь идет о нашем коде, обрушивающийся поток нам тоже вряд-ли будет полезным. Во всяком случае необходимости в этом я не встречал. Наша задача - обработать ошибки правильно, отдать информацию об их возникновении в журнал ошибок и корректно завершить работу потока. Т.е. по сути обернуть метод, с которого стартует поток в try-catch:
ThreadPool.QueueUserWorkitem(_ => {
using(Disposables aggregator = ...){
try {
// do work here, plus:
aggregator.Add(subscriptions);
aggregator.Add(dependantResources);
} catch (Exception ex)
{
logger.Error(ex, "Unhandled exception");
}
}
});
В такой схеме мы получим то что надо: с одной стороны мы не обрушим поток. С другой - корректно очистим локальные ресурсы если они были созданы. Ну и в довесок - организуем журналирование полученной ошибки. Но постойте, скажете вы. Как-то вы лихо соскочили с вопроса события AppDomain.UnhandledException. Неужели оно совсем не нужно? Нужно. Но только для того чтобы сообщить что мы забыли обернуть какие-то потоки в try-catch со всей необходимой логикой. Именно со всей: с логгированием и очисткой ресурсов. Иначе это будет совершенно не правильно: брать и гасить все исключения, как будто их и не было вовсе.
Виды исключений
Практически все исключения на платформе .NET выглядят абсолютно одинаково. И это свойство в первую очередь - заслуга разработчиков ядра платформы. Ведь то что мы получаем по своей сути является унификацией разнородных источников ошибок. Особенно это чувствуется на Core CLR, где наши приложения исполняются как на Windows, так и на Linux или OS X. Как же можно поделить исключительные ситуации? Я бы предложил поделить их как-то так:
- Пользовательские исключения. Это те исключения, которые выбрасываются при помощи инструкции CLR
throw. Все что выброшено данным способом является пользовательским. А это значит что никаких особенностей их перехвата не существует; - Исключения платформы CLR. Это - специальный тип исключений, которые генерируются из внутренностей платформы. Эти исключения могут обладать особыми свойствами поведения, о которых стоит помнить;
- Исключения unsafe кода пользовательского уровня. Как правило перехватываются без особых проблем;
- Исключения unsafe кода уровня операционной системы. Чаще всего имеют очень специализированные свойства при перехвате.
Однако несмотря на их изобилие практически все из них за редким исключением могут быть обработаны.
Исключения платформы CLR
ThreadAbortException
Вообще, это может показаться не очевидным, но существует четыре типа Thread Abort.
- Грубый вариант ThreadAbort, который, отрабатывая не может быть никак остановлен и который не запускает обработчиков исключительных ситуаций вообще включая секции
finally - Вызов метода Thread.Abort() на текущем потоке
- Асинхронное исключение ThreadAbortException, вызванное из другого потока
- Если во время выгрузки AppDomain существуют потоки, в рамках которых запущены методы, скомпилированные для этого домена, будет произведен ThreadAbort тех потоков, в которых эти методы запущены
Стоит заметить что ThreadAbortException довольно часто используется в большом .NET Framework, однако его не существует на CoreCLR, .NET Core или же под Windows 8 "Modern app profile". Попробуем узнать, почему.
Итак, если мы имеем дело с не принципиальным типом обрыва потока, когда мы еще можем с ним что-то сделать (т.е. второй, третий и четвертый вариант), виртуальная машина при возникновении такого исключения начинает идти по всем обработчикам исключительных ситуаций и искать как обычно те, тип исключения которых является тем, что было выброшено либо более базовым. В нашем случае это три типа: ThreadAbortException, Exception и object (помним что Exception - это по своей сути - хранилище данных и тип исключения может быть любым. Даже int). Отрабатывая все подходящие catch блоки виртуальная машина пробрасыват ThreadAbortException дальше по цепочке обработки исключений попутно входя во все finally блоки. В целом, ситуации в двух примерах, описанных ниже абсолютно одинаковые:
var thread = new Thread(() =>
{
try {
// ...
} catch (Exception ex)
{
// ...
}
});
thread.Start();
//...
thread.Abort();
var thread = new Thread(() =>
{
try {
// ...
} catch (Exception ex)
{
// ...
if(ex is ThreadAbortException)
{
throw;
}
}
});
thread.Start();
//...
thread.Abort();
Конечно же, всегда возникнет ситуация, когда возникающий ThreadAbort может быть нами вполне ожидаем. Тогда может возникнуть понятное желание его все-таки обработать. Как раз для таких случаев был разработан и открыт метод Thread.ResetAbort(), который делает именно то, что нам нужно: останавливает сквозной проброс исключения через всю цепочку обработчиков, делая его обработанным:
void Main()
{
var barrier = new Barrier(2);
var thread = new Thread(() =>
{
try {
barrier.SignalAndWait(); // Breakpoint #1
Thread.Sleep(TimeSpan.FromSeconds(30));
}
catch (ThreadAbortException exception)
{
"Resetting abort".Dump();
Thread.ResetAbort();
}
"Catched successfully".Dump();
barrier.SignalAndWait(); // Breakpoint #2
});
thread.Start();
barrier.SignalAndWait(); // Breakpoint #1
thread.Abort();
barrier.SignalAndWait(); // Breakpoint #2
}
Output:
Resetting abort
Catched successfully
Однако реально ли стоит этим пользоваться? И стоит ли обижаться на разработчиков CoreCLR что там этот код попросту выпилен? Представьте что вы - пользователь кода, который по вашему мнению "повис" и у вас возникло непреодолимое желание вызвать для него ThreadAbortException. Когда вы хотите оборвать жизнь потока все чего вы хотите - чтобы он действительно завершил свою работу. Мало того, редкий алгоритм просто обрывает поток и бросает его, уходя к своим делам. Обычно внешний алгоритм решает дождаться корректного завершения операций. Или же наоборот: может решить что поток более уже ничего делать не будет, декрементирует некие внутренние счетчики и более не будет завязываться на то что есть какая-то многопоточная обработка какого-либо кода. Тут в общем не скажешь, что хуже. Я даже так вам скажу: отработав много лет программистом я до сих пор не могу вам дать прекрасный способ его вызова и обработки. Сами посудите: вы бросаете ThreadAbort не прямо сейчас а в любом случае спустя некоторое время после осознания безвыходности ситуации. Т.е. вы можете как попасть по обработчику ThreadAbortException так и промахнуться мимо него: "зависший код" мог оказаться вовсе не зависшим, а попросту долго работающим. И как раз в тот момент, когда вы хотели оборвать его жизнь, он мог вырваться из ожидания и корректно продолжить работу. Т.е. без лишней лирики выйти из блока try-catch(ThreadAbortException) { Thread.ResetAbort(); }. Что мы получим? Оборванный поток, который ни в чем не виноват. Шла уборщица, выдернула провод, сеть пропала. Метод ожидал таймаута, уборщица вернула провод, все заработало, но ваш контролирующий код не дождался и убил поток. Хорошо? Нет. Как-то можно защититься? Нет. Но вернемся к навящивой идее легализации Thread.Abort(): мы кинули кувалдой в поток и ожидаем что он с вероятностью 100% оборвется, но этого может не произойти. Во-первых становится не понятно как его оборвать в таком случае. Ведь тут все может быть намного сложнее: в подвисшем потоке может быть такая логика, которая перехватывает ThreadAbortException, останавливает его при помощи ResetAbort, однако продолжает висеть из-за сломанной логики. Что тогда? Делать безусловный thread.Interrupt()? Попахивает попыткой обойти ошибку в логике программы грубыми методами. Плюс, я вам гарантирую что у вас поплывут утечки: thread.Interrupt() не будет заниматься вызовом catch и finally, а это значит что при всем опыте и сноровке очистить ресурсы вы не сможете: ваш поток просто исчезнет, а находясь в соседнем потоке вы можете не знать ссылок на все ресурсы, которые были заняты умирающим потоком. Также прошу заметить что в случае промаха ThreadAbortException мимо catch(ThreadAbortException) { Thread.ResetAbort(); } у вас точно также потекут ресурсы.
После того что вы прочитали чуть выше я надеюсь, вы остались в некотором состоянии запутанности и желания перечитать абзац. И это будет совершенно правильная мысль: это будет доказательством того что пользоваться Thread.Abort() попросту нельзя. Как и нельзя пользоваться thread.Interrupt();. Оба метода приводят к неконтролируемому поведению вашего приложения. По своей сути они нарушают принцип целостности: основной принцип .NET Framework.
Однако, чтобы понять для каких целей этот метод введен в эксплуатацию достаточно посмотреть исходные коды .NET Framework и найти места использования Thread.ResetAbort(). Ведь именно его наличие по сути легализует thread.Abort().
Класс ISAPIRuntime ISAPIRuntime.cs
try {
// ...
}
catch(Exception e) {
try {
WebBaseEvent.RaiseRuntimeError(e, this);
} catch {}
// Have we called HSE_REQ_DONE_WITH_SESSION? If so, don't re-throw.
if (wr != null && wr.Ecb == IntPtr.Zero) {
if (pHttpCompletion != IntPtr.Zero) {
UnsafeNativeMethods.SetDoneWithSessionCalled(pHttpCompletion);
}
// if this is a thread abort exception, cancel the abort
if (e is ThreadAbortException) {
Thread.ResetAbort();
}
// IMPORTANT: if this thread is being aborted because of an AppDomain.Unload,
// the CLR will still throw an AppDomainUnloadedException. The native caller
// must special case COR_E_APPDOMAINUNLOADED(0x80131014) and not
// call HSE_REQ_DONE_WITH_SESSION more than once.
return 0;
}
// re-throw if we have not called HSE_REQ_DONE_WITH_SESSION
throw;
}
В данном примере происходит вызов некоторого внешнего кода и если тот был завершен не корректно: с ThreadAbortException, то при определенных условиях помечаем поток как более не прерываемый. Т.е. по сути обрабатываем ThreadAbort. Почему в данном конкретно случае мы обрываем Thread.Abort? Потому что в данном случае мы имеем дело с серверным кодом, а он в свою очередь вне зависимости от наших ошибок вернуть корректные коды ошибок вызывающей стороне. Обрыв потока привел бы к тому что сервер не смог бы вернуть нужный код ошибки пользователю, а это совершенно не правильно. Также оставлен комментарий о Thread.Abort() во время AppDomin.Unload(), что является экстримальной ситуацией для ThreadAbort поскольку такой процесс не остановить и даже если вы сделаете Thread.ResetAbort. Это хоть и остановит сам Abortion, но не остановит выгрузку потока с доменом, в котором он находится: поток же не может исполнять инструкции кода, загруженного в домен, который отгружен.
Класс HttpContext HttpContext.cs
internal void InvokeCancellableCallback(WaitCallback callback, Object state) {
// ...
try {
BeginCancellablePeriod(); // request can be cancelled from this point
try {
callback(state);
}
finally {
EndCancellablePeriod(); // request can be cancelled until this point
}
WaitForExceptionIfCancelled(); // wait outside of finally
}
catch (ThreadAbortException e) {
if (e.ExceptionState != null &&
e.ExceptionState is HttpApplication.CancelModuleException &&
((HttpApplication.CancelModuleException)e.ExceptionState).Timeout) {
Thread.ResetAbort();
PerfCounters.IncrementCounter(AppPerfCounter.REQUESTS_TIMED_OUT);
throw new HttpException(SR.GetString(SR.Request_timed_out),
null, WebEventCodes.RuntimeErrorRequestAbort);
}
}
}
Здесь приведен прекрасный пример перехода от неуправляемого асинхронного исключения ThreadAbortException к управляемому HttpException с логгированием ситуации в журнал счетчиков производительности.
Класс HttpApplication HttpApplication.cs
internal Exception ExecuteStep(IExecutionStep step, ref bool completedSynchronously)
{
Exception error = null;
try {
try {
// ...
}
catch (Exception e) {
error = e;
// ...
// This might force ThreadAbortException to be thrown
// automatically, because we consumed an exception that was
// hiding ThreadAbortException behind it
if (e is ThreadAbortException &&
((Thread.CurrentThread.ThreadState & ThreadState.AbortRequested) == 0)) {
// Response.End from a COM+ component that re-throws ThreadAbortException
// It is not a real ThreadAbort
// VSWhidbey 178556
error = null;
_stepManager.CompleteRequest();
}
}
catch {
// ignore non-Exception objects that could be thrown
}
}
catch (ThreadAbortException e) {
// ThreadAbortException could be masked as another one
// the try-catch above consumes all exceptions, only
// ThreadAbortException can filter up here because it gets
// auto rethrown if no other exception is thrown on catch
if (e.ExceptionState != null && e.ExceptionState is CancelModuleException) {
// one of ours (Response.End or timeout) -- cancel abort
// ...
Thread.ResetAbort();
}
}
}
Здесь описывается очень интересный случай: когда мы ждем не настоящий ThreadAbort (мне вот в некотором смысле жалко команду CLR и .NET Framework. Сколько не стандартных ситуаций им приходится обрабатывать, подумать страшно). Обработка ситуации идет в два этапа: внутренним обработчиком мы ловим ThreadAbortException но при этом проверяем наш поток на флаг реальной прерываемости. Если поток не помечен как прерывающийся, то на самом деле это не настоящий ThreadAbortException. Такие ситуации мы должны обработать соответствующим образом: спокойно поймать исключение и обработать его. Если же мы получаем настоящий ThreadAbort, то он уйдет во внешний catch поскольку ThreadAbortException должен войти во все подходящие обработчики. Если он удовлетворяет необходимым условиям, он также будет обработан путем очистки флага ThreadState.AbortRequested методом Thread.ResetAbort().
Если говорить про примеры самого вызова Thread.Abort(), то все примеры кода в .NET Framework написаны так что могут быть переписаны без его использования. Для наглядности приведу только один:
Класс QueuePathDialog QueuePathDialog.cs
protected override void OnHandleCreated(EventArgs e)
{
if (!populateThreadRan)
{
populateThreadRan = true;
populateThread = new Thread(new ThreadStart(this.PopulateThread));
populateThread.Start();
}
base.OnHandleCreated(e);
}
protected override void OnFormClosing(FormClosingEventArgs e)
{
this.closed = true;
if (populateThread != null)
{
populateThread.Abort();
}
base.OnFormClosing(e);
}
private void PopulateThread()
{
try
{
IEnumerator messageQueues = MessageQueue.GetMessageQueueEnumerator();
bool locate = true;
while (locate)
{
// ...
this.BeginInvoke(new FinishPopulateDelegate(this.OnPopulateTreeview), new object[] { queues });
}
}
catch
{
if (!this.closed)
this.BeginInvoke(new ShowErrorDelegate(this.OnShowError), null);
}
if (!this.closed)
this.BeginInvoke(new SelectQueueDelegate(this.OnSelectQueue), new object[] { this.selectedQueue, 0 });
}
TheradAbortException во время AppDomain.Unload
Попробуем отгрузить AppDomain во время исполнения кода, который в него загружен. Для этого искусственно создадим не вполне нормальную ситуацию, но достаточно интересную с точки зрения исполнения кода. В данном примере у нас два потока: один создан для того чтобы получить в нем ThreadAbortException, а другой - основной. В основном мы создаем новый домен, в котором запускаем новый поток. Задача этого потока - уйти в основной домен. Чтобы методы дочернего домена осталиь бы только в Stack Trace. После этого основной домен отгружает дочерний:
class Program : MarshalByRefObject
{
static void Main()
{
try
{
var domain = ApplicationLogger.Go(new Program());
Thread.Sleep(300);
AppDomain.Unload(domain);
} catch (ThreadAbortException exception)
{
Console.WriteLine("Main AppDomain aborted too, {0}", exception.Message);
}
}
public void InsideMainAppDomain()
{
try
{
Console.WriteLine($"InsideMainAppDomain() called inside {AppDomain.CurrentDomain.FriendlyName} domain");
// AppDomain.Unload will be called while this Sleep
Thread.Sleep(-1);
}
catch (ThreadAbortException exception)
{
Console.WriteLine("Subdomain aborted, {0}", exception.Message);
// This sleep to allow user to see console contents
Thread.Sleep(-1);
}
}
public class ApplicationLogger : MarshalByRefObject
{
private void StartThread(Program pro)
{
var thread = new Thread(() =>
{
pro.InsideMainAppDomain();
});
thread.Start();
}
public static AppDomain Go(Program pro)
{
var dom = AppDomain.CreateDomain("ApplicationLogger", null, new AppDomainSetup
{
ApplicationBase = AppDomain.CurrentDomain.BaseDirectory,
});
var proxy = (ApplicationLogger)dom.CreateInstanceAndUnwrap(typeof(ApplicationLogger).Assembly.FullName, typeof(ApplicationLogger).FullName);
proxy.StartThread(pro);
return dom;
}
}
}
Происходит крайне интересная вещь. Код выгрузки домена помимо самой выгрузки ищет вызванные в этом домене методы, которые еще не завершили работу в том числе в глубине стека вызова методов и вызывает ThreadAbortException в этих потоках. Это важно, хоть и не очевидно: если домен отгружен, нельзя осуществить возврат в метод, из которого был вызван метод основного домена, но который находится в отгружаемом. Т.е. другими словами AppDomain.Unload может выбрасывать потоки, исполняющие в данный момент код из других доменов. Прервать Thread.Abort в таком случае не получится: исполнять код выгруженного домена вы не сможете, а значит Thread.Abort завершит свое дело, даже если вы вызовите Thread.ResetAbort.
Выводы по ThreadAbortException
- Это - асинхронное исключение, а значит оно может возникнуть в любой точке вашего кода (но, стоит отметить, что для этого надо постараться);
- Обычно код обрабатывает только те ошибки, которые ждет: нет доступа к файлу, ошибка парсинга строки и прочие подобные. Наличие асинхронного (в плане возникновения в любом месте кода) исключения создает ситуацию, когда try-catch могут быть не обработаны: вы же не можете быть готовым к ThreadAbort в любом месте приложения. И получается, что это исключение в любом случае породит утечки;
- Обрыв потока может также происходить из-за выгрузки какого-либо домена. Если в Stack Trace потока существуют вызовы методов отгружаемого домена, поток получит ThreadAbortException без возможности
ResetAbort; - В общем случае не должно возникать ситуаций, когда вам нужно вызвать Thread.Abort(), поскольку результат практически всегда - не предсказуем.
- CoreCLR более не содержит ручной вызов
Thread.Abort(): он просто удален из класса. Но это не означает что его нет возможности получить.
ExecutionEngineException
В комментарии к этому исключению стоит атрибут Obsolete с комментарием:
This type previously indicated an unspecified fatal error in the runtime. The runtime no longer raises this exception so this type is obsolete
И вообще-то это - неправда. Возможно, автору комментария очень бы хотелось чтобы это когда-либо стало правдой, однако чтобы продемонстрировать что это не так, достаточно вернуться к примеру исключения в FirstChanceException:
void Main()
{
var counter = 0;
AppDomain.CurrentDomain.FirstChanceException += (_, args) => {
Console.WriteLine(args.Exception.Message);
if(++counter == 1) {
throw new ArgumentOutOfRangeException();
}
};
throw new Exception("Hello!");
}
Результатом данного кода будет ExecutionEngineException, хотя ожидаемое мной поведение Unhandled Exception ArgumentOutOfRangeException из инструкции throw new Exception("Hello!"). Возможно это показалось страным разработчикам ядра и они посчитали что корректнее выбросить ExecutionEngineException.
Второй вполне простой путь получить ExecutionEngineException - это не корректно настроить маршаллинг в мир unsafe. Если вы напутаете с размерами типов, передадите больше чем надо, чем испортите, например, стек потока, ждите ExecutionEngineException. И это будет логичный, правильный результат: ведь в данной ситуации CLR вошла в состояние, которое она нашла не консистентным. Не понятным, как его восстанавливать. И как результат, ExecutionEngineException.
Отдельно стоит поговорить про диагностику ExecutionEngineException:
- Используются ли в вашем приложении unsafe библиотеки? Вами или же может сторонними библиотеками. Попробуйте для начала выяснить, где конкретно приложение получает данную ошибку. Если код уходит в unsafe мир и получает
ExecutionEngineExceptionтам, тогда необходимо тщательно проверить сходимость сигнатур методов: в нашем коде и в импортируемом. Помните что если импортируются модули написанные на Delphi и прочих вариациях языка Pascal, то аргументы должны идти в обратном порядке (настройка производится вDllImport:CallingConvention.StdCall; - Подписаны ли вы на FirstChanceException? Возможно его код вызвал исключение. В таком случае просто оберните обработчик в
try-catch(Exception)и обязательно сохраните в журнал ошибок происходящее; - Может быть ваше приложение частично собрано под одну платформу, а частично - под другую. Попробуйте очистить кэш nuget пакетов, полностью пересобрать приложение с нуля: с очищенными вручную папками obj/bin
- Проблема иногда бывает в самом фреймворке. Например, в ранних версиях .NET Framework 4.0. В этом случае стоит протестировать отдельный участок кода, который вызывает ошибку - на более новой версии фреймворка;
В целом бояться этого исключения не стоит: оно возникает достаточно редко чтобы позабыть о нем до следующей радостной с ним встречи.
AccessViolationException
Выброс этого исключения - одна из тех новостей, которые не хотелось бы никому получить. А когда получаешь, становится совсем не ясно что с этим делать. AccessViolationException - это исключение "промаха" мимо выделенного для приложения участка памяти и по своей сути выбрасывается при попытке чтения или записи в защищенную область памяти. Здесь под словом "защита" лучше понимать именно попытку работы с еще не выделенным участком памяти или же уже освобожденным. Тут, заметьте не имеется ввиду процесс выделения и освобождения памяти сборщиком мусора. Тот просто размечает уже выделенную память под свои и ваши нужды. Память - она имеет в некоторой степени слоистую структуру. Когда после слоя управления памятью сборщиком мусора идет слой управления выделением памяти операционной системой - из пула доступных фрагментов линейного адресного пространства. Так вот когда приложение промахивается мимо своей памяти и пытается работать с невыделенным участком, тогда и возникает это исключение. Когда оно возникает, вам доступно не так много вариантов для анализа:
- Если StackTrace уходит в недра CLR, вам сильно не повезло: это скорее всего ошибка ядра. Однако этот случай почти никогда не срабатывает. Из вариантов обхода - либо действовать как-то иначе либо обновить версию ядра если возможно;
- Если же StackTrace уходит в unsafe код некоторой библиотеки, тут доступны такие варианты: либо вы напутали с настройкой маршаллинга либо же в unsafe библиотеке закралась серьезная ошибка. Тщательно проверьте аргументы метода: возможно аргументы нативного метода имеют другую разрядность или же другой порядок или попросту размер. Проверьте что структуры передаются там где надо - по ссылке, а там, где надо - по значению
Чтобы перехватить такое исключение на данный момент необходимо показать JIT компилятору что это реально необходимо. В противном случае оно перехвачено никак не будет и вы получите упавшее приложение. Однако, конечно же, его стоит перехватывать только тогда, когда вы понимаете что вы сможете его правильно обработать: его наличие может свидетельствовать о произошедшей утечке памяти если она была выделена unsafe методом между точкой его вызова и точкой выброса AccessViolationException и тогда хоть приложение и не будет "завалено", но его работа возможно станет не корректной: ведь перехватив поломку вызова метода вы наверняка попробуете вызвать этот метод еще раз, в будущем. А в этом случае что может пойти не так не известно никому: вы не можете знать каким образом было нарушено состояние приложения в прошлый раз. Однако, если желание перехватить такое исключение у вас сохранилось, прошу посмотреть на таблицу возможности перехвата этого исключения в различных версиях .NET Framework:
| Версия .NET Framework | AccessViolationExeception |
|---|---|
| 1.0 | NullReferenceException |
| 2.0, 3.5 | AccessViolation перехватить можно |
| 4.0+ | AccessViolation перехватить можно, но необходима настройка |
| .NET Core | AccessViolation перехватить нельзя |
Т.е. другими словами, если вам попалоось очень старое приложение на .NET Framework 1.0, ~~покажите его мне~~ вы получите NRE, что будет в некоторой степени обманом: вы отдали указатель со значением больше нуля, а получили NullReferenceException. Однако, на мой взгляд, такое поведение обосновано: находясь в мире управляемого кода вам меньше всего должно хотеться изучать типы ошибок неуправляемого кода и NRE - что по сути и есть "плохой указатель на объект" в мире .NET - тут вполне подходит. Однако, мир был бы прекрасен если бы все так было просто. В реальных ситуациях пользователям решительно не хватало этого типа исключений и потому - достаточно скоро - его ввели в версии 2.0. Просуществовав несколько лет в перехватываемом варианте, исключение перестало быть перехватываемым, однако появилась специальная настройка, которая позволяет включить перехват. Такой порядок выбора в команде CLR в целом на каждом этапе выглядит достаточно обоснованным. Посудите сами:
1.0Ошибка промаха мимо выделенных участков памяти должна быть именно исключительной ситуацией потому как если приложение работает с каким-либо адресом, оно его откуда-то получило. В managed мире этим местом является операторnew. В unmanaged мире - в целом любой участок кода может выступать точкой для возникновения такой ошибки. И хотя с точки зрения философии смысл обоих исключений диаметрально противоположен (NRE - работа с не проинициализированным указателем, AVE - работа с некорректно проинициализированным указателем), с точки зрения идеологии .NET некорректно проинициализированных указателей быть не может. Оба случая можно свести к одному и придать философский смысл: не корректно заданный указатель. А потому давайте так и сделаем: в обоих случаях будем выбрасыватьNullReferenceException.2.0На ранних этапах существования .NET Framework оказалось что кода, который наследуется через COM библиотеки больше собственного: существует огромная кодовая база коммерческих компонент для взаимодействия с сетью, UI, БД и прочими подсистемами. А значит, вопрос получения именноAccessViolationExceptionвсе-таки стоит: неверная диагностика проблем может сделать процесс поимки проблемы более дорогим. В .NET Framework введено исключениеAccessViolationException.4.0.NET Framework укоренился, потеснив традиционную разработку на низкоуровневых узыках программирования. Резко сокращено количество COM компонент: практически все основные задачи уже решаются в рамках самого фреймворка, а работа в unsafe кодом начинает считаться чем-то странным, неправильным. В этих условиях можно вернуться к идеологии, введенной в фреймворк с самого начала: .NET - он только для .NET. Unsafe код - это не норма, а вынужденное состояние, а потому идеологичность наличия перехватаAccessViolationExceptionидет вразрез с идеологией понятия фреймворк - как платформа (т.е. имитация полной песочницы со своими законами). Однако мы все еще находимся в реалиях платформы, на которой работаем и во многих ситуациях перехватывать это исключение все еще необходимо: вводим специальный режим перехвата: только если введена соответствующая конфигурация;.NET CoreНаконец, сбылась мечта команды CLR: .NET более не предполагает законности работы с unsafe кодом, а потому существованиеAccessViolationExceptionтеперь вне закона даже на уровне конфигурации. .NET вырос настолько чтобы самостоятельно устанавливать правила. Теперь существование этого исключения в приложении приведет его к гибели, а потому любой unsafe код (т.е. сам CLR) обязан быть безопасным с точки зрения этого исключения. Если оно появляется в unsafe библиотеке, с ней просто не будут работать, а значит разработчики сторонних компонент на unsafe языках будут более аккуратными и обрабатывать его - у себя.
Вот так, на примере одного исключения можно проследить историю становления .NET Framework как платформы: от неуверенного подчинения внешним правилам до самостоятельного установления правил самой платформой.
После всего сказанного осталось раскрыть последнюю тему: как включить обработку данного исключения в 4.0+. Итак, чтобы включить обработку исключения данного типа в конкретном методе, необходимо:
- Добавить в секцию
configuration/runtimeследующий код:<legacyCorruptedStateExceptionsPolicy enabled="true|false"/> - Для каждого метода, где необходимо обработать
AccessViolationException, надо добавить два атрибута:HandleProcessCorruptedStateExceptionsиSecurityCritical. Эти атрибуты позволяют включить обработку Corrupted State Exceptions, для конкретных методов, а не для всех вообще. Эта схема очень правильная, поскольку вы должны быть точно уверены что хотите их обрабатывать и знать, где: иногда более правильный вариант - просто завалить приложение на бок.
Для примера включения обработчика CSE и их примитивной обработки рассмотрим следующий код:
[HandleProcessCorruptedStateExceptions]
[SecurityCritical]
public bool TryCallNativeApi()
{
try
{
// Запуск метода, который может выбросить AccessViolationException
}
catch (Exception e)
{
// Журналирование, выход
System.Console.WriteLine(e.Message);
return false;
}
return true;
}
NullReferenceException
SecurityException
OutOfMemoryException
StackOverflowException
Выводы
Также стоит остановиться на том, для чего же были введены фильтры исключений. Давайте взглянем на пример и он как по мне будет лучше тысячи слов:
try {
UnmanagedApiWrapper.SomeMethod();
} catch (WrappedException ex) when (ex.ErrorCode == ErrorCodes.DeviceNotFound)
{
// ...
} catch (WrappedException ex) when (ex.ErrorCode == ErrorCodes.ConnectionLost)
{
// ...
} catch (WrappedException ex) when (ex.ErrorCode == ErrorCodes.TimeOut)
{
// ...
} catch (WrappedException ex) when (ex.ErrorCode == ErrorCodes.Disconnected)
{
// ...
}
Согласитесь, это выглядит интереснее чем один блок catch и switch внутри с throw; в default блоке. Это выглядит более разграниченным, более правильным с точки зрения разделения ответственности. Ведь исключение с кодом ошибки по своей сути - ошибка дизайна, а фильтрация - это выправка нарушения архитектуры, переводя в концепцию раздельных типов исключений.
Виды исключительных ситуаций
TODO
- FailFast